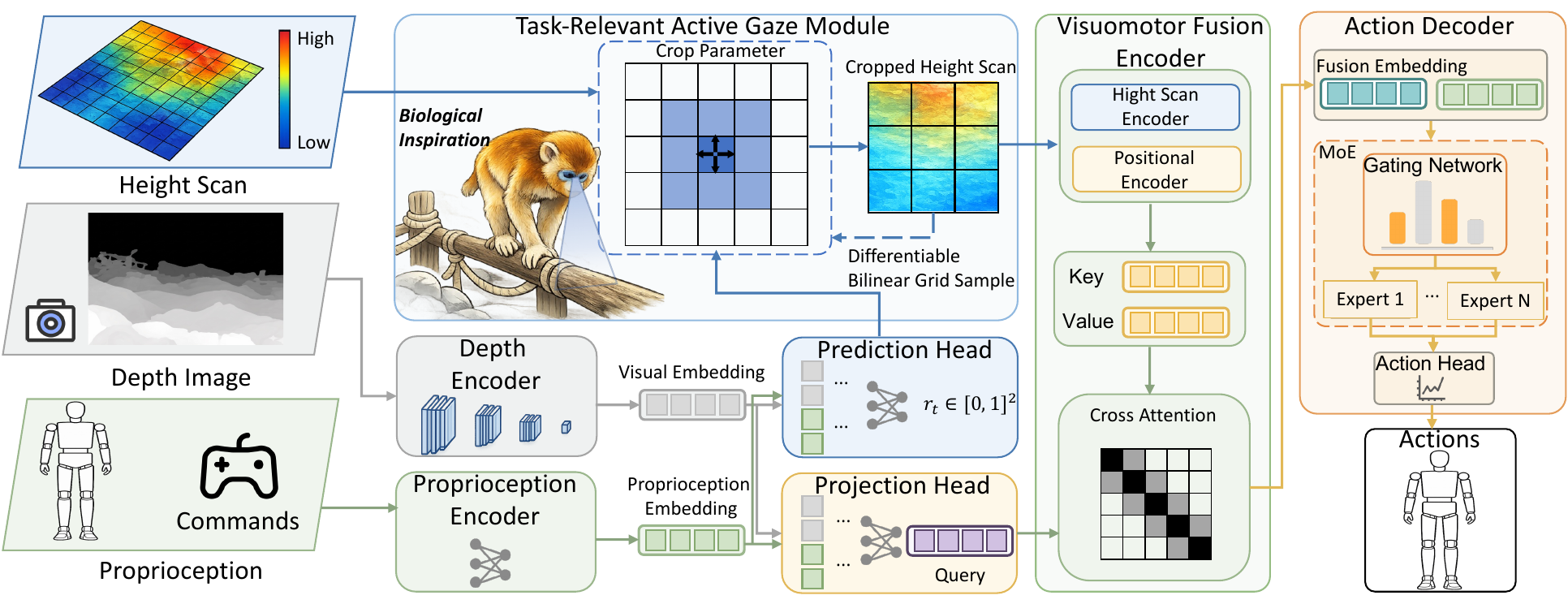
TAGA: Terrain-aware Active Gaze Learning for Generalizable Agile Humanoid Locomotion
A terrain-aware active gaze learning framework for agile and generalizable humanoid locomotion across gaps, sparse footholds, stairs, narrow beams, and outdoor terrain.
LI Peizhuo1,*,
Hongyi LI2,*,
Mingfeng FAN1,*,
Fangzhou XU1,
Shuhao LIAO1,
Yuxuan MA1,
Zicheng ZENG3,
Ze WANG2,
Yongbin JIN2,†,
Yuhong CAO1,†,
Hongtao WANG2,
Guillaume SARTORETTI1
1MarmotLab, National University of Singapore 2Center of X-Mechanics, Zhejiang University 3South China University of Technology
*Equal contribution †Corresponding authors Under Review